주요 학습 내용 요약
Numpy, DataFrame, Series 이해하기
2. DataFrame & Series
- DataFrame과 Series가 들어있는 pandas 불러오기
!pip install pandas
import pandas as pd - Series : 1차원 데이터

- index를 설정할 수 도 있다.
: ls_series = pd.Series(ls, index = [‘a’,’b’,’e’]) - DataFrame : 2차원 데이터 (Series가 여러개)

- df.values, df.index, df.dtypes, df.columns
- 데이터프레임 상위 행, 하위 행 확인하기
: .head(행의 개수), .tail(행의 개수)
- 데이터프레임 요약 정보 확인하기
: .info(), 컬럼명 null값 object
: .describe, 개수 평균 분산 4분위수
- 데이터 조회하기
행 : df[index:index]
열 : df[ 컬럼명 ], df.컬럼명, df[ 컬럼명 ].to_frame(), df[ [ 컬럼이름s ] ]
df.loc[행조건,열조건], df.loc[:,열조건] 열만 조회, df.loc[[]] 행만 조회
iloc : 위치 인덱스로 조회, 3:4 적힌 위치 다 포함 3,4행 표현
- 데이터 추출

- 조건에 맞는 새로운 열 만들기


- 데이터 업데이트

- 집합 합수, 기술통계
df.sum(), df.mean(numeric_only=True), df.max(), df.min()
df.describe(), df.info()
- sort_values 정렬하기

- 인덱스 변경
몇개를 바꿀 때 df.rename({기존인덱스: 바꿀 인덱스, ,,}) # df 자체 데이터 변경은 아님
전체를 바꿀 때 df.index = 바꿀 인덱스 리스트
인덱스를 열로 변환 : 기존 열 남길때 df.reset_index() / 기존 열 삭제 df.reset_index(drop=True)
- 행
행 추가 pd.concat([기존 데이터명, 붙일 데이터명])
행 제거 df.drop(인덱스명, axis=0) df.drop([i for i in range(891, len(df3)]) 절반 데이터 삭제
행 중복 제거 df.drop_duplicates()
- 열
열 추가 df[추가할 컬럼명] = 추가할 값
열 제거 df.drop(제거할 컬럼명, axis=1)
df[‘name’].str.split(‘,’) 특정 문자열 기준으로 자르기
ex ) df[‘given_name’] = [i[0] for i in df[‘name’].str.split(‘,’)]
열 이름 변경 df.rename({열이름:바꿀이름, 열이름:바꿀이름, …}, axis=1)
df.columns = 열이름 리스트

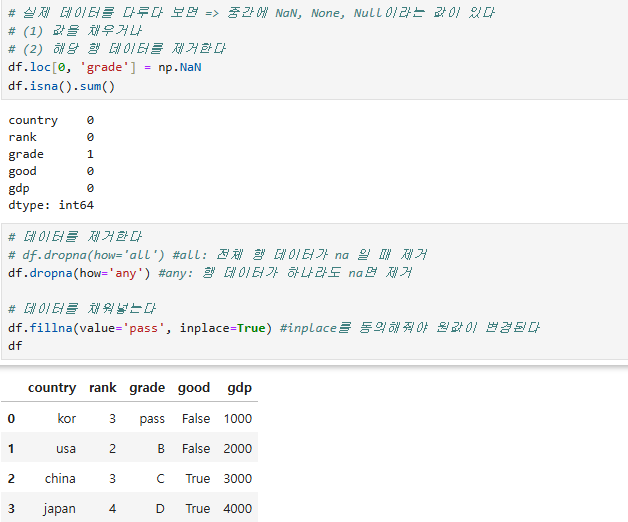
- 결측값 확인
: isna: 결측값을 True로 반환 / notna : 결측값을 False로 반환
df.isna().sum() 결측값 합계 / df[df[‘age’].isna()] 결측값이 있는 행들만 조회
결측값 제거
: df.dropna(axis=0, how=’any’, subset=None)
axis: { 0:index/1:columns } / how: {‘any’:존재하면 제거/’all’:모두 결측치면 제거}
subset: 행/열의 이름을 지정합니다.
결측값 대치
df.fillna(대치할값) 데이터 전체의 결측값을 특정 값으로 변경
df[컬럼명].fillna(대치할 값) 특정 컬럼의 결측값을 특정 값으로 변경
df.fillna(method=’ffill’) 결측값을 바로 위의 값과 동일하게 변경
df.fillna(method=’bfill’) 결측값을 바로 아래의 값과 동일하게 변경
- 타입 확인
df.dtypes
df.select_dtype(‘int’), (‘object’==str) 특정 타입의 데이터만 조회
타입 변환 df[컬럼].astype(타입) 기존데이터 변경 원할시 덧씌워주기
df[‘age’].fillna(-1).astype(int) 결측치를 -1로 바꾸고 age를 정수로 변환하기
- 결측치를 다시 돌려놓기
import numpy as np
df[‘age’]=df[‘age’].fillna(-1).astype(int).replace(-1, np.nan)
- 문자형을 날짜형으로 변경
pd.to_datatime(컬럼, format=’날짜형식’)

- 날짜를 원하는 형식으로 변경
df[‘컬럼’].dt.strftime(날짜형식)
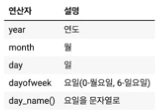
dt 연산자 df[‘year’] = df[‘date’].dt.year
- 날짜 계산
day 연산 : pd.Timedelta(days=숫자)
: df[‘plus_day1’] = df[‘date’]+pd.Timedelta(days=1month 연산 : DateOffset(months=숫자)
: from pandas.tseries.offsets import Dateoffset
year 연산 : Dateoffset(years=숫자)
- 날짜 구간 데이터 만들기
pd.date_range(start=시작일자, end=종료일자, periods=기간수, freq=주기)

pd.date_range(start=’2025-01-06’, periods=30, freq=’D’) 하루씩, 30개 가져오기
- 기간 이동 계산
컬럼.rolling().집계함수
df[‘ma7’] = df[‘Temp’].rolling(7).mean() 이동평균
min() 이동최소값, max() 이동최대값
- 행 이동
컬럼.shift(이동할 행의 수)
df[‘Temp shift’] = df[‘temp’].shift(1) 한 행 씩 밀려 쓰기
df[‘pct change’] = (df[‘Temp shift’] - df[‘temp’]) df[‘temp’] 전날 대비 변화율
shift(-1) 앞으로 한 칸 땡기기
데이터 불러오기, 저장하기
- csv 파일
불러오기 : 데이터변수 = pd.read_csv(파일경로)
저장하기 : 데이터변수.to_csv(파일경로)
read_csv(파일경로, index_col=? 열 인덱스로 지정)
read_csv(파일경로, usecols = [] 특정 열들만 사용할거야) - 엑셀 파일
불러오기 : 데이터변수 = pd.read_excel(파일경로, sheet_name=시트이름)
저장하기 : 데이터변수 = pd.to_excel(파일경로, sheet_name=시트이름)
pd.read_excel(파일경로, header = 컬럼 이름으로 사용할 행, index_col, usecols) - 웹 html 파일
pd.read_html(html경로, encoding = 한글이 깨져 나올 때 utf-8/cp949로 설정)
'패스트캠퍼스' 카테고리의 다른 글
| [패스트캠퍼스] 데이터 분석 부트캠프 17기 - 5주차 (2) pyplot (0) | 2025.01.13 |
|---|---|
| [패스트캠퍼스] 데이터 분석 부트캠프 17기 - 5주차 (1) 농구선수 분석 (0) | 2025.01.13 |
| [패스트캠퍼스] 데이터 분석 부트캠프 17기 - 4주차 (3) Numpy (0) | 2025.01.12 |
| [패스트캠퍼스] 데이터 분석 부트캠프 17기 - 4주차 (2) 크롤링 실습 API (0) | 2025.01.12 |
| [패스트캠퍼스] 데이터 분석 부트캠프 17기 - 4주차 (1) 크롤링 실습 셀레늄 (0) | 2025.01.11 |