주요 학습 내용 요약
CH04. 탐색적 데이터 분석 (2)
- 상관 분석과 산점도
상관분석 : 두 변수가 어떤 관계(+/-)인지 분석
상관관계 : 한쪽이 증가하면 증가/감소의 통계적 관계
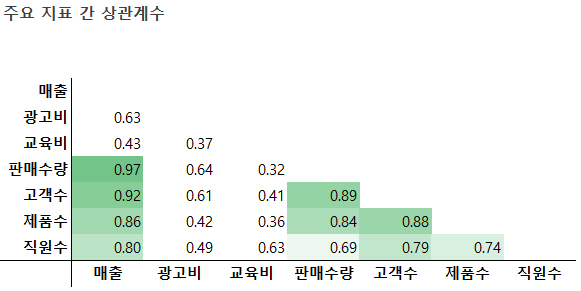
상관계수 : r, 보편적으로 피어슨 상관계수, -1(반비례) <= r =< 1(비례),
0에 가까울수록 관계가 없다.
그러나 이것이 인과관계를 표현하는 것은 아님. 인과관계는 실험을 통해 경험적으로 입증해야 함.
데이터 - 데이터분석 - 상관분석 - 분류 포함하여 범위설정, 첫째행 이름표, 출력범위 빈칸 하나 넣기 - 확인
1 지워주고 - 데이터 선택 - 조건부 서식 - 규칙관리 - 새규칙 - 1.셀 값 기준 모든 셀의 서식 지정 - 3가지 색조
- 종류 숫자로 바꾸기 - 최소 :-1, 최대 :1 - 중간값 색깔 흰색 지정 - 확인
음의 상관관계가 없고, 평균 값이 높다. 0.65

CH05. 데이터 전처리
- 분석 목적과 방법에 맞게 가공 처리 하는 과정
- 분석 과정 중 가장 많은 시간과 비용이 필요, Garbage in, Garbage out
- (복습) vlookup 열을 기준으로 데이터 불러오기
vlookup(찾을 기준 데이터, 불러올 데이터 범위, 불러올 데이터 열 번호 - 공통 기준열 1, 0 정확히 일치 or 1 근사치)
- 이때 불러올 데이터 열번호를 표현하는 방법
1. 열에 번호 적어놓고, 셀 참조하기 - 최초의 한번은, 필요 열의 번호를 알아내야 하는 번거로움
2. match 함수를 사용하여 필요열의 넘버 반환하기
= match(현재 셀에서 찾고자 하는 열이름 선택, 찾아올 열 범위(한 행 / 한 열), 0 or 1)
= VLOOKUP($C12, LIST!$D:$J, MATCH($D$11,LIST!$D$4:$J$4, 0), 0)
= INDEX(범위, 행번호(1부터시작), 열번호(1부터시작))
= COUNTIFS(결과범위, 범위, 조건, 범위, 조건)
= FIND(찾을 텍스트, 전체 텍스트, 문자열을 찾기 시작할 위치) -> 대소문자 구분
첫 번째 텍스트 시작할 위치 = 1 -> 두번째 텍스트 시작할 위치 = 첫번째 위치 + 1
= SEARCH() -> 대소문자 구분 X
리뷰에서 특정 키워드가 있으면 숫자 출력, 아니면 #VALUE 에러가 출력됨
-> 이를 0으로 반환하기 위해서 =IFERROR(FIND(‘맛’, 범위, 1), 0)
= LEFT(전체 텍스트, 불러올 문자열 수 ), = RIGHT()
= MID(전체 텍스트, 불러올 문자열의 시작 위치, 불러올 문자열 수) | mid(문자,5,3) -> soo
= LEN(문자) -> 문자열의 길이
날짜 데이터 : 0000-00-00 / =YEAR(), =MONTH(), =DAY / =DATE(셀, 셀, 셀) -> 0000-00-00
시간 데이터 : =HOUR(), =MINUTE(), =SECOND() <-> =TIME()
텍스트 나누기 : 데이터 - 텍스트나누기
CH06. 데이터 분석 / 모델링 - 통계적 분석 기법
- 통계학은 관심 대상인 모집단으로부터 표본의 특성을 파악하는 것이다.
- 부분으로 전체를 알고자 하는 노력. 그러나 편향될 수 있으므로 주의해야 함.
- 기술 통계학 : 요약 통계량, 그래프 표 등을 이용해 데이터를 정리, 요약하여 데이터의 전반적인 특성을 파악하는 방법 ex) max, min, 막대 그래프, 꺾은선형 차트, 합계, 평균 등을 보기
- 추론 통계학 : 모집단 중 일부 표본 추출하여 통계학으로 추축.
- 가설검정
귀무가설(H0, 영가설) - 기본적으로 참. 처음부터 의미가 없는 경우.
대립가설(H1, 연구가설) - 귀무가설에 대립하는 명제.
대립가설이 참이다를 증명하는 것이 아니라, 귀무가설을 기각하는 것이 목표이다.
가설 검정의 기준 : p-value(유의 확률)
예를들어,
- 귀무가설 : 돼지 10,000마리의 평균 체중은 100kg이다.
- 귀무가설이 참인지 증명하기 위해, 무작위로 돼지 100마리를 선정해 평균 체중 측정
-> 표본에 따라 다양한 평균값이 나올 수 있음
-> 하지만 전체 평군이 진짜 100kg라면 표본의 평균값도 100kg근처에서 형성 가능성이 큼
-> 전체 평균이 100kg일 때 표본의 평균이 30kg나올 확률은 5% 미만임
-> 그런데 우리가 추출한 표본의 평균이 30kg 가 나왔다면?
-> 전체의 평균이 100kg이 아닐 것이라고 강하게 의심
- 유의수준(p)
- 보다 유의확률이 작아야, 귀무가설을 기각할 수 있다.
평균의 값보다 아주 이상한 값이 나올 확률 = 유의 확률
통상적으로 p = 5% = 0.05 - 변수(집단) 선택 -> F-검정 -> t-test -> 검증
(1) F-검정 : 분산에 통계적으로 유의미한 차이가 있는지.
귀무가설 - 두 집단의 분산에 유의미한 차이가 없다 (p >= 유의수준) - 분산이 같다. -> 등분산가정
대립가설 - 유의미한 차이가 있다 (p < 유의수준) - 분산이 다르다 -> 이분산가정
(2) t-test : 두 집단(또는 한 집단의 전/후)의 평균이 통계적으로 유의미한 차이가 있는지 결정
양측 검정 : 차이가 있다.
단측 검정 : -보다 크다. -보다 작다.
p < 0.05 유의미한 차이가 있다 !
새롭게 알게 된 점 또는 깊이 있게 이해한 내용
left, right, mid, len 함수를 이용하여 문자를 다루는 실습을 하였다.
이 함수들을 활용하는 방법을 처음 알게 되었지만 간단한 사용법이기에 잘 따라갈 수 있었다.
실습을 하며 엑셀의 단축키를 쓰는게 점점 익숙해 지는게 느껴진다.오랜만에 t-test를 보아서 반가웠다. t-test는 공부할 때 마다 까먹어서 매번 처음에는 헤맨다.이번에는 강사님이 문과적인(?) 방식으로 설명을 해 주셔서 더 쉽게 이해할 수 있었다.이 개념을 이제 다시는 까먹지 않을 수 있도록 공부해야겠다.
추가로 조사한 관련 정보나 응용 방안
F-검정하기 : F 기각치 이용


=T.TEST(그룹 1, 그룹 2, tails, type)
그룹 1과 그룹 2는 비교하고자 하는 샘플 데이터 집합.
tails는 단측이면 1, 양측이면 2.
type은 대응 표본이면 1, 독립 표본 등분산이면 2, 독립 표본 이분산이면 3입니다.
[출처] https://blog.naver.com/dotorimj2/222271586254
'패스트캠퍼스' 카테고리의 다른 글
| [패스트캠퍼스] 데이터 분석 부트캠프 17기 - 2주차 통계 온라인강의(2) (1) | 2024.12.27 |
|---|---|
| [패스트캠퍼스] 데이터 분석 부트캠프 17기 - 2주차 통계 온라인강의(1) (0) | 2024.12.27 |
| [패스트캠퍼스] 데이터 분석 부트캠프 17기 - 1주차 데이터분석기초 줌강의(1) (1) | 2024.12.22 |
| [패스트캠퍼스] 데이터 분석 부트캠프 17기 - 1주차 Excel 온라인강의 (2) 엑셀 기능, 엑셀 시각화 (1) | 2024.12.19 |
| [패스트캠퍼스] 데이터 분석 부트캠프 17기 - 1주차 Excel 온라인강의 (1) 엑셀 기초, 엑셀 함수 (0) | 2024.12.19 |